



The table of content
Introduction
The FC + CVX line is a high‑throughput veneer production line where multiple modules (Clipper, CVX, intermediate conveyors, storage, stacker) must work in tight synchronisation to deliver stable output at the planned speed. Even small disturbances in availability, performance, or quality can quickly accumulate into hours of lost productive time, yet in many plants the only visible metric is a single OEE value at the end of the day or shift. Traditional reports from MES or spreadsheets provide aggregated numbers but do not explain where exactly time is lost, whether the line is starved of material, blocked by full buffers, waiting for an operator, or stopped by technical faults. This creates a gap between the complexity of the equipment and the simplicity of the KPIs used to manage it, making it hard to identify real bottlenecks and to agree on priorities between production, maintenance, and management.
The purpose of this use case is to close that gap by turning raw PLC signals from the FC + CVX line into a transparent, second‑by‑second view of how the line is used, and by clearly quantifying all “lost hours” inside planned production time. The solution builds a consistent OEE model that calculates Availability, Performance, and Quality for every shift, day, product, and module, while also breaking down downtime into meaningful categories such as No Material, Blocked, Changeover, Maintenance, Fault, and Operator Break. For management, this provides a single source of truth to understand where efficiency is gained or lost and to justify investments with data. For maintenance, it separates technical issues from organisational and material‑related stops, supporting preventive actions and better planning. For operators and shift supervisors, the dashboards become a daily tool that shows how their decisions and reactions affect OEE in real time and highlights concrete opportunities to increase output without new machinery.
Data and Virtual State Model
The use case builds on data that already exists in the customer’s automation and production systems and organises it into a consistent virtual view of how the FC + CVX line behaves over time. At the base layer are detailed PLC signals from all main modules of the line, including drives, transports, shears, buffers, stackers, infrastructure readiness, safety circuits, material presence, and operator commands; this is enriched with production orders, shift calendars, and quality information provided by MES or ERP systems. Together, these inputs describe not only whether the machine is electrically and pneumatically ready, but also whether material is present at each critical point, whether buffers are full, whether safety devices are active, and what product and speed targets apply in a given period.
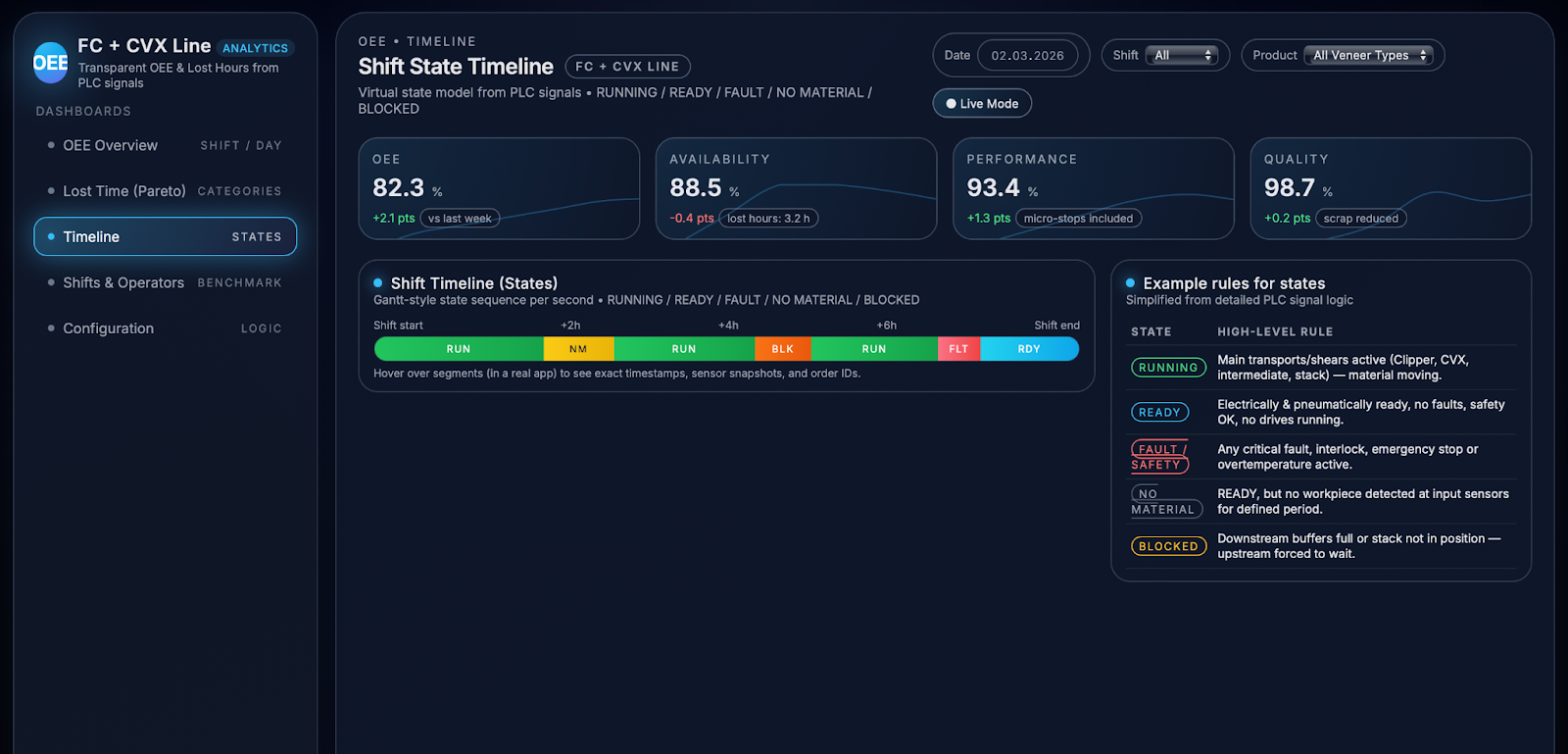
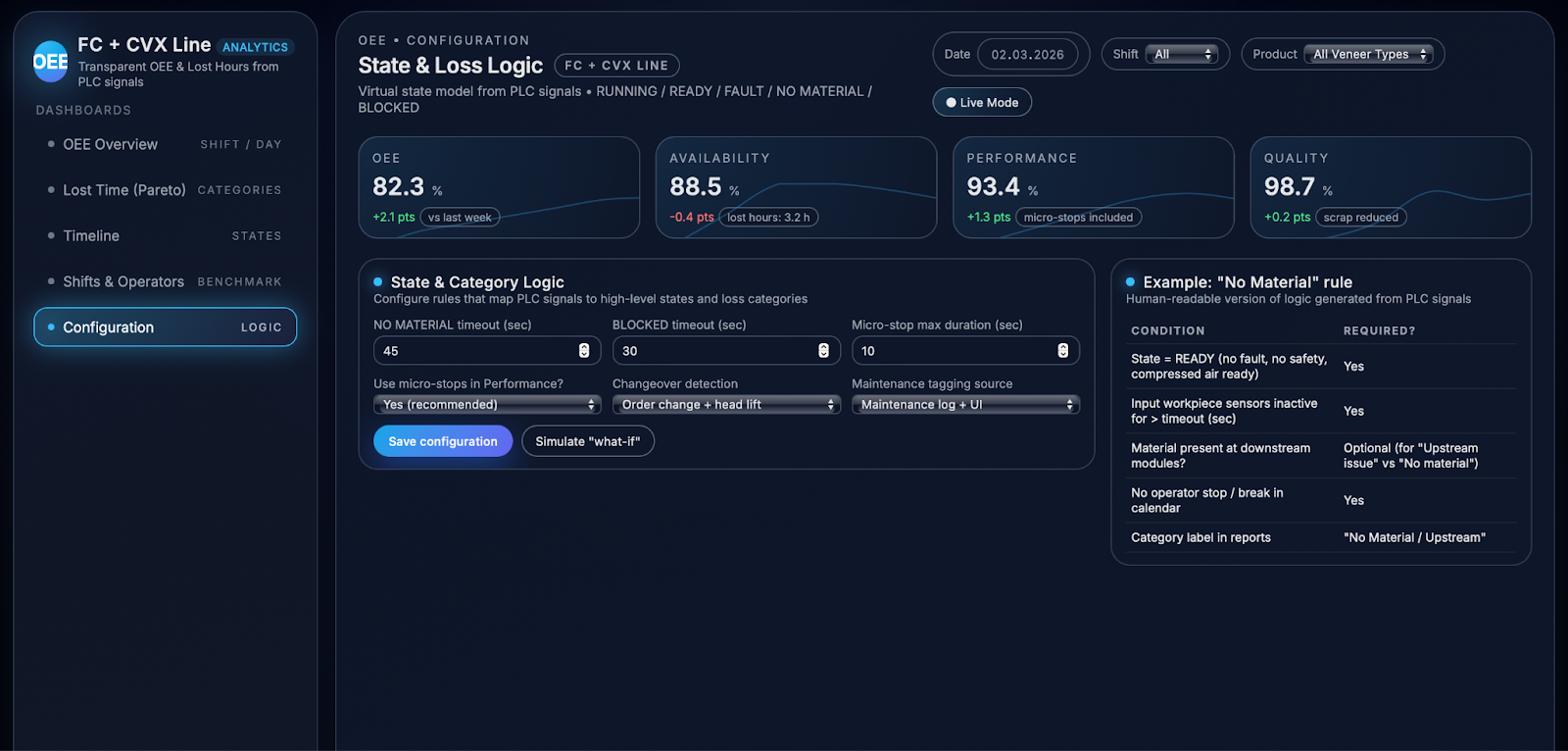
To make this information usable for operations, the solution constructs a virtual state model that classifies every second of line behaviour into a small number of high‑level states: RUNNING, READY, FAULT, NO MATERIAL, and BLOCKED. RUNNING covers all moments when at least one of the main transports or shears is actively moving material; READY indicates that the line is technically ready (power, compressed air, safety all OK) but no drives are running; FAULT represents any critical fault, interlock, or safety stop; NO MATERIAL captures periods when the line is READY but material sensors show no workpieces at the input for longer than a defined threshold; and BLOCKED describes situations where upstream sections are forced to wait because downstream storage or stack sensors indicate full buffers or “stack not in position”. These states provide a shared language that is easy to understand for operators, engineers, and managers.
Under the hood, state transitions are driven by explicit rule logic that combines multiple signals, conditions, and timeouts so that states remain stable and meaningful rather than flickering with every short sensor change. For example, the logic will only switch into READY when breaker and compressed‑air signals are healthy, HVAC and overtemperature alarms are clear, all safety fences and interlocks are closed, and no main drive is running; it moves into NO MATERIAL only if relevant input sensors remain inactive for more than a configured number of seconds, and into BLOCKED when downstream “buffer full” or “stack not in position” signals stay active beyond their timeout. Every resulting state is logged continuously, typically with a one‑second resolution, creating a time series that shows exactly how long the line spent in each condition, in which order states occurred, and how they align with orders and shifts. This continuous state history is the foundation for all subsequent analytics: it defines planned versus operating time, enables precise OEE calculation, powers Pareto breakdowns of lost hours, and drives visualisations such as timelines and benchmarking views.
OEE Calculation and Lost Hours Analytics
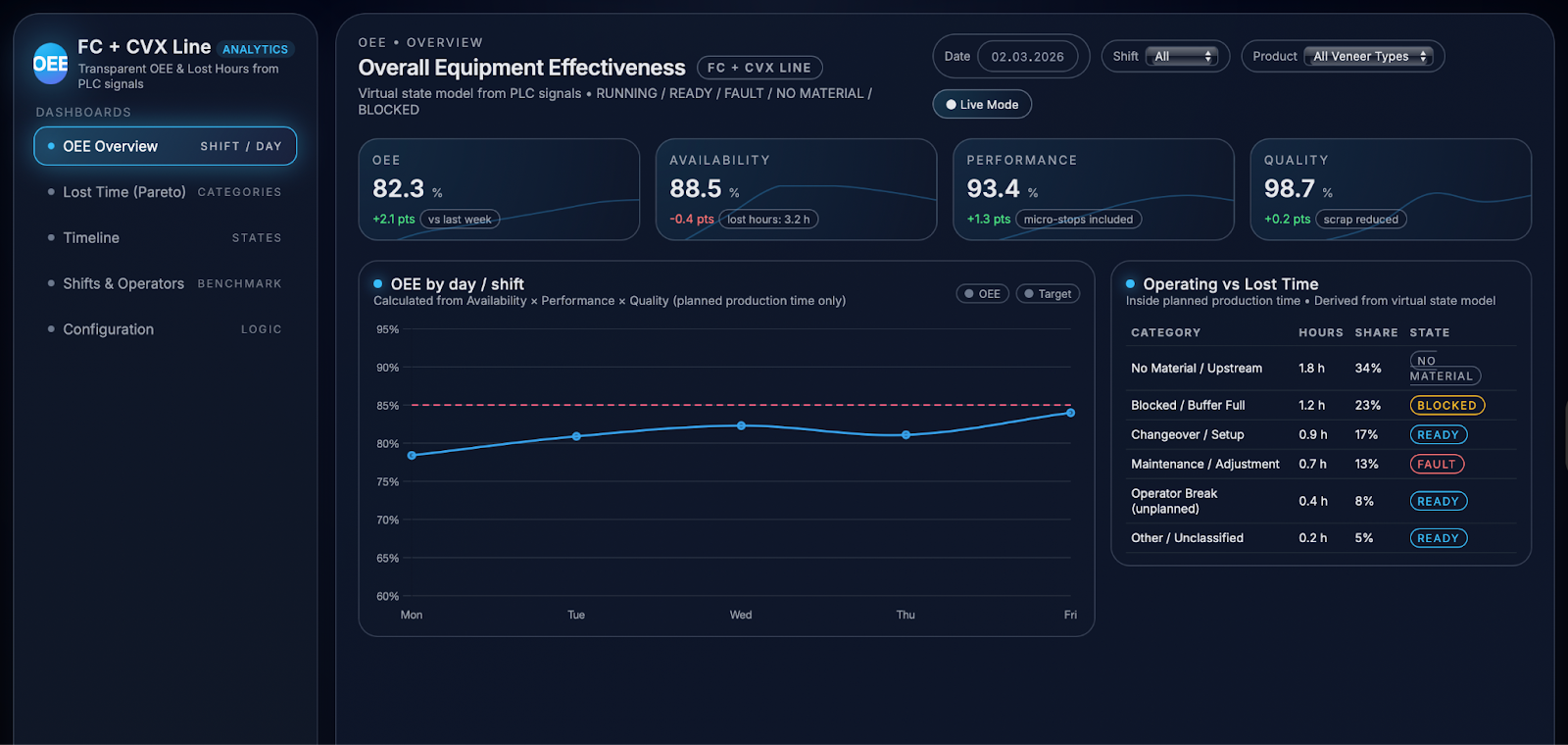
The analytics layer builds directly on the virtual state model to calculate OEE in a way that is both fully automated and easy to interpret in daily operations. Planned production time for each shift or day is derived from the production calendar, excluding scheduled breaks and planned maintenance, and defines the window in which OEE is evaluated. Within this window, operating time is defined as all periods when the line is RUNNING, plus optional micro‑stops that are short enough to be treated as part of normal operation rather than as separate downtime; the threshold for such micro‑stops can be tuned to each customer. Time spent in non‑productive states such as NO MATERIAL, BLOCKED, FAULT, MAINTENANCE, or longer operator‑related stops is excluded from operating time and instead contributes to “lost hours”, making the impact of each non‑running condition explicitly visible.
From this foundation, the system calculates the three OEE components for every relevant slice of the process: per shift, per day, per product, and per module of the FC + CVX line. Availability expresses the ratio between operating time and planned production time and is directly linked to the proportion of time spent in productive vs non‑productive states. Performance compares actual throughput against the ideal throughput derived from nominal or target speed per product, using workpiece detection sensors and counters to measure how many sheets or joints were actually processed in each interval. Quality is determined from customer data on good versus scrap output per period, synchronised with the same timeline as states and throughput. Combining these three components yields OEE as a single KPI for each time slice, but the dashboards always allow users to drill down into the underlying components and see how they evolve over time.
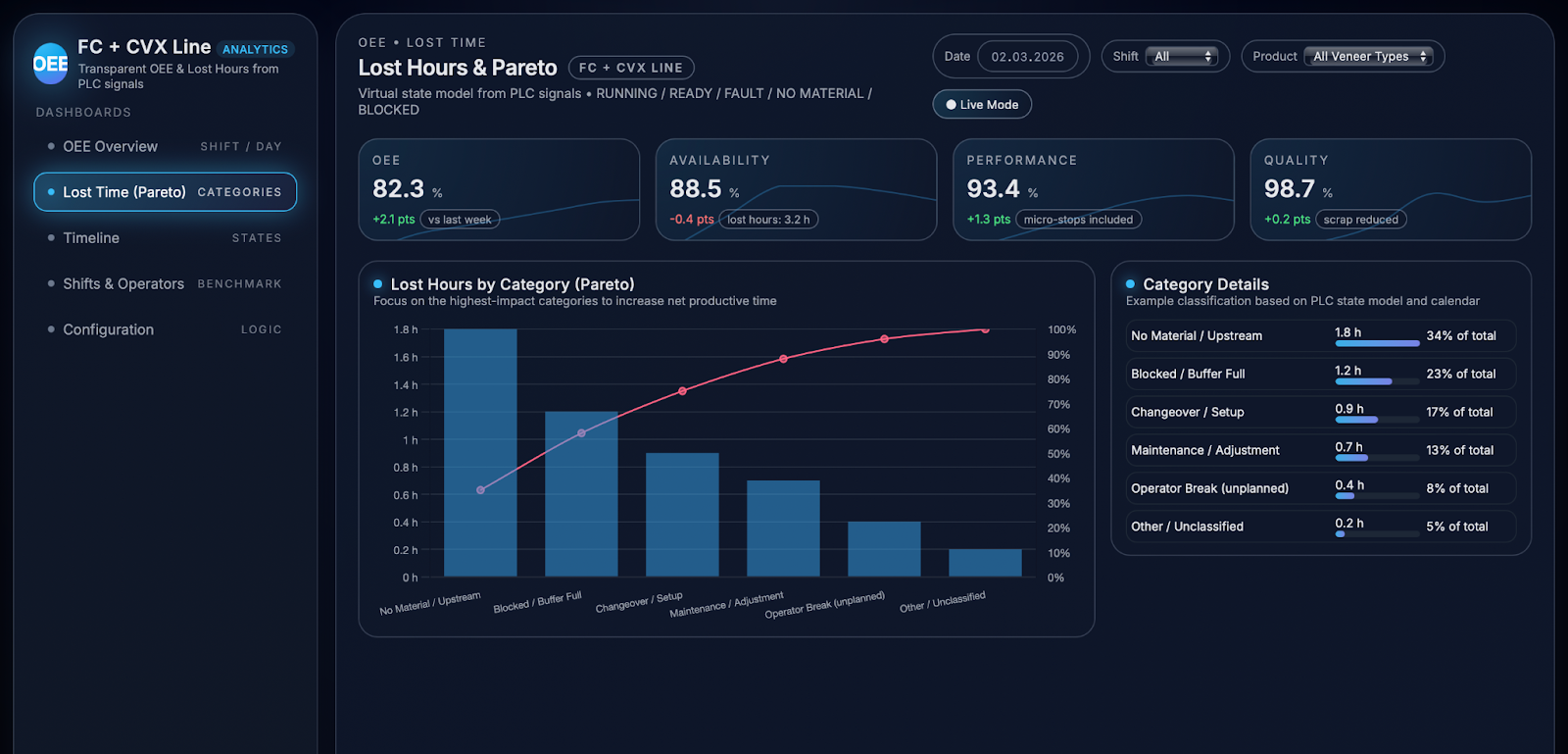
Within planned production time, any second when the line is not producing good output is treated as a potential “lost hour” and is classified according to the state model, sensor patterns, operator actions, and calendar context. The analytics engine examines all non‑RUNNING intervals and assigns them to clearly defined loss categories, turning diffuse impressions of “downtime” into measurable buckets of waste. Typical categories include No Material, where the line is READY but upstream sensors show no workpieces; Blocked, where upstream sections are waiting because downstream buffers or stacks are full or not in position; Operator Break / No Operator, where the machine is READY and material is present but no start command is given outside scheduled breaks; Changeover / Setup, where the line is intentionally stopped or running in special modes during order changes and alignment; Maintenance and Adjustment, where protective fences are open or interlocks are active in line with maintenance actions; Fault / Safety Stops, where the line is in FAULT due to technical or safety issues; and an Other category for intervals that do not yet match any rule and can be refined over time.
On the OEE overview dashboard, these calculations come together in a compact view that shows OEE, Availability, Performance, and Quality across days and shifts, alongside a breakdown of operating versus lost time. Users can immediately see how today compares to last week, which shifts are closest to the target line, and whether changes in OEE are driven more by availability, performance, or quality. A dedicated Lost Hours & Pareto view then sorts loss categories by impact, using bars and cumulative curves to highlight where most productive time is being lost and how each category contributes to the overall gap between actual and potential output. This combination of high‑level KPIs with detailed loss analytics enables teams to move from abstract discussions about “low OEE” to very concrete, data‑backed improvement actions focused on the categories that matter most.
Dashboards and Use Cases
The dashboards translate the underlying data model into views that are directly usable in daily operations and decision‑making on the FC + CVX line. A central element is the timeline view, which presents a full shift as a Gantt‑style sequence of colour‑coded machine states such as RUNNING, READY, FAULT, NO MATERIAL, and BLOCKED, making it easy to see when and where production actually flowed and where it stopped. Orders, changeovers, and selected operator actions can be overlaid on this timeline, so engineers and supervisors can visually correlate state changes with specific events, for example identifying that a long NO MATERIAL period consistently appears after certain orders, or that repeated BLOCKED intervals coincide with stack changes on the downstream equipment.
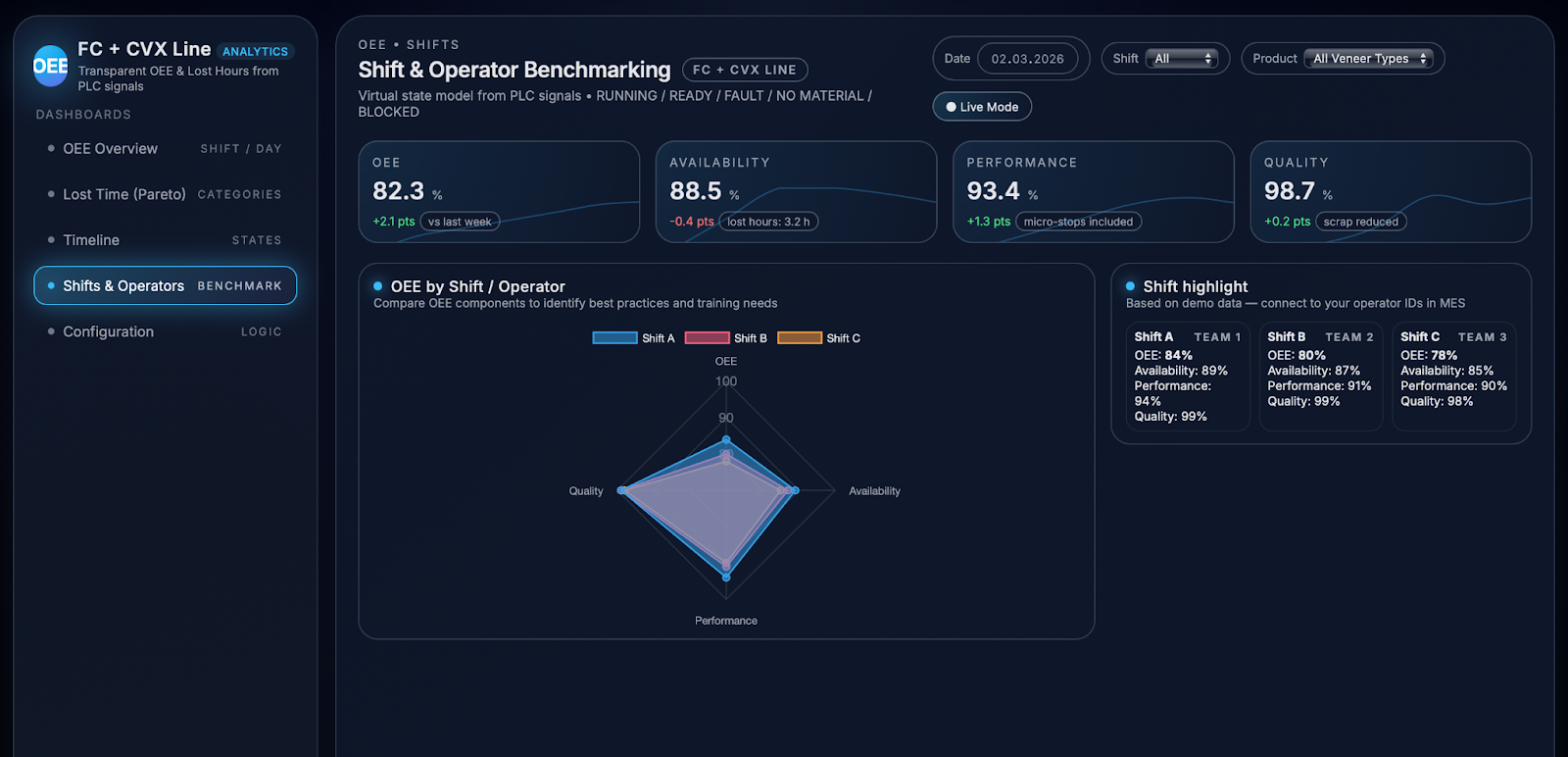
To understand differences in behaviour between teams, the solution includes a shift and operator benchmarking view that aggregates OEE components and lost‑hours categories for each shift or operator ID. Radar charts and compact comparison panels show, at a glance, which shifts achieve higher availability or fewer “No Material” and “Blocked” losses, and which ones spend more time in changeovers or unplanned breaks. This not only highlights best performers and practices that can be shared, but also reveals specific training needs, such as teams that require support in changeover standardisation or in reacting to early signals of buffer blocking. Because the same logic is applied consistently to all shifts and operators, discussions about performance become fact‑based rather than anecdotal.
The analytics can be delivered as a standalone application or integrated into the customer’s existing digital ecosystem. Interfaces to MES, ERP, and maintenance systems ensure that order information, calendars, and maintenance logs stay in sync, while OEE and lost‑hours KPIs can be exposed to tools such as Power BI or Grafana for broader reporting. Role‑based access makes it possible to tailor views for management, engineers, and operators, ensuring that each group sees the level of detail it needs without overloading the interface. This tight integration reduces manual reporting effort and makes the analytics part of the standard workflow rather than an extra step.
Business Value
From a business perspective, the dashboards turn OEE from a static KPI into a practical improvement tool. By showing exactly where time is lost and how this pattern changes over days and weeks, they help teams prioritise actions with the highest leverage, whether that is improving material logistics to reduce NO MATERIAL time, adjusting buffer and stack‑handling processes to cut BLOCKED losses, or standardising changeovers. Even relatively small gains in availability or performance translate directly into additional productive hours on the existing equipment, postponing or reducing the need for capital investments. At the same time, the quantified breakdown of losses provides a solid, data‑driven basis for justifying investments when they are needed, such as additional buffers, automation around stack handling, or extra staffing on specific shifts. Over time, this combination of transparency, feedback, and measurable impact supports a continuous improvement culture in which management, maintenance, and operators work from the same facts and can see the results of their decisions on the FC + CVX line.
Conclusions and Next Steps
The implementation of full OEE and lost‑hours analytics on the FC + CVX line has turned raw machine data into a shared, operational picture of how the line actually runs over time. The team now has transparent visibility of when the line is RUNNING, READY, starved of material, blocked by downstream equipment, or stopped due to faults, maintenance, or operator‑related reasons, all quantified down to seconds within planned production time. Instead of debating why OEE is low in general, managers, engineers, and operators can see a factual breakdown of losses by category, shift, product, and module, which has already enabled targeted actions such as reducing “No Material” time, smoothing stack changes, and tightening changeover procedures. As a result, the FC + CVX line has gained measurable improvements in net productive time and stability without any additional investment in hardware, while also reducing manual reporting effort and ambiguity in performance discussions.
The next step is to treat this use case as a template for the wider production network. Because the approach relies mainly on existing PLC and MES/ERP data, the same virtual state model and OEE logic can be adapted to other lines and plants with similar architecture, gradually building a consistent analytics layer across the factory. Additional use cases can be added on top of the same data foundation, for example deeper maintenance analytics based on recurring fault patterns, energy‑per‑throughput monitoring, or early‑warning alerts for rising loss categories. Over time, the rule‑based classification of lost hours can be enhanced with machine‑learning components that automatically refine thresholds, detect new patterns in downtime, and suggest the most likely root causes for unexplained losses. This roadmap turns the FC + CVX line from a single successful project into a scalable analytics platform that supports continuous improvement and data‑driven decision‑making across the entire production system.



Our success stories
















.avif)











































Tell us about your project needs











.png)
.png)