



The table of content
Introduction
Purpose and Solution Overview
A leading telecom operator managing large-scale RAN and tower infrastructure faced growing operational pressure due to increasing network complexity and rising service expectations. With thousands of distributed assets and high traffic variability, even minor equipment degradation could quickly escalate into service disruptions affecting large customer segments. The client’s existing maintenance approach was primarily reactive, limiting their ability to prevent failures and optimize field operations at scale.
To address this challenge, an AI-driven predictive maintenance and field operations orchestration solution was designed and implemented specifically for the client’s environment. The platform integrates real-time telemetry, OSS alarms, historical failure data, and external factors such as weather conditions to detect early degradation patterns and predict potential failures in advance. This enables a shift from reactive incident handling to proactive, data-driven decision-making.
In addition to predictive capabilities, the solution introduces intelligent orchestration of field operations. By prioritizing sites based on risk, SLA impact, and traffic load, and by automating dispatch recommendations and maintenance planning, the platform significantly improves operational efficiency. As a result, the client gains full visibility into asset health, faster response times, and a scalable foundation for managing network performance proactively.
Business Challenge
Operational Limitations
of Reactive Maintenance
The client operates a highly distributed telecom infrastructure spanning RAN equipment, power systems, and tower assets across multiple regions. As network complexity increased, the limitations of a reactive maintenance model became more visible. Failures were typically identified only after service degradation or alarm escalation, leaving little room for preventive action and resulting in operational inefficiencies across both network performance and field operations.
This approach created a chain reaction of issues. Delayed fault detection led to extended service disruptions, while the lack of early diagnostics increased the time required to identify root causes and dispatch field engineers. At the same time, field operations were not optimized, leading to unnecessary truck rolls, inefficient routing, and suboptimal use of workforce resources.
Key challenges included:
- Increased network downtime caused by late detection of equipment failures
- High Mean Time to Repair (MTTR) due to delayed diagnostics and reactive dispatching
- Excessive truck rolls resulting in elevated operational costs and inefficient field operations
- SLA breaches leading to financial penalties and declining customer satisfaction
Revenue loss driven by poor network performance and service instability
Additionally, the absence of early anomaly detection resulted in cascading failures across interdependent network elements. Issues in power systems, for example, could propagate to RAN equipment, amplifying the overall impact and increasing operational risk across the network.
Solution
AI-Driven Predictive Maintenance Platform
To address the limitations of reactive maintenance, a tailored AI-driven predictive maintenance and field operations orchestration platform was implemented for the client. The solution introduces an intelligence layer on top of existing OSS, telemetry streams, and field service systems, enabling a shift toward proactive, data-driven operations.
At its core, the platform continuously analyzes real-time and historical data to identify early signs of equipment degradation and predict failures before they impact network performance. This allows the client to move from reactive incident response to preventive and optimized operational workflows.
The solution delivers several core capabilities. It predicts failures across critical telecom assets, including BBU, RRU, batteries, rectifiers, and generators, hours to days in advance.
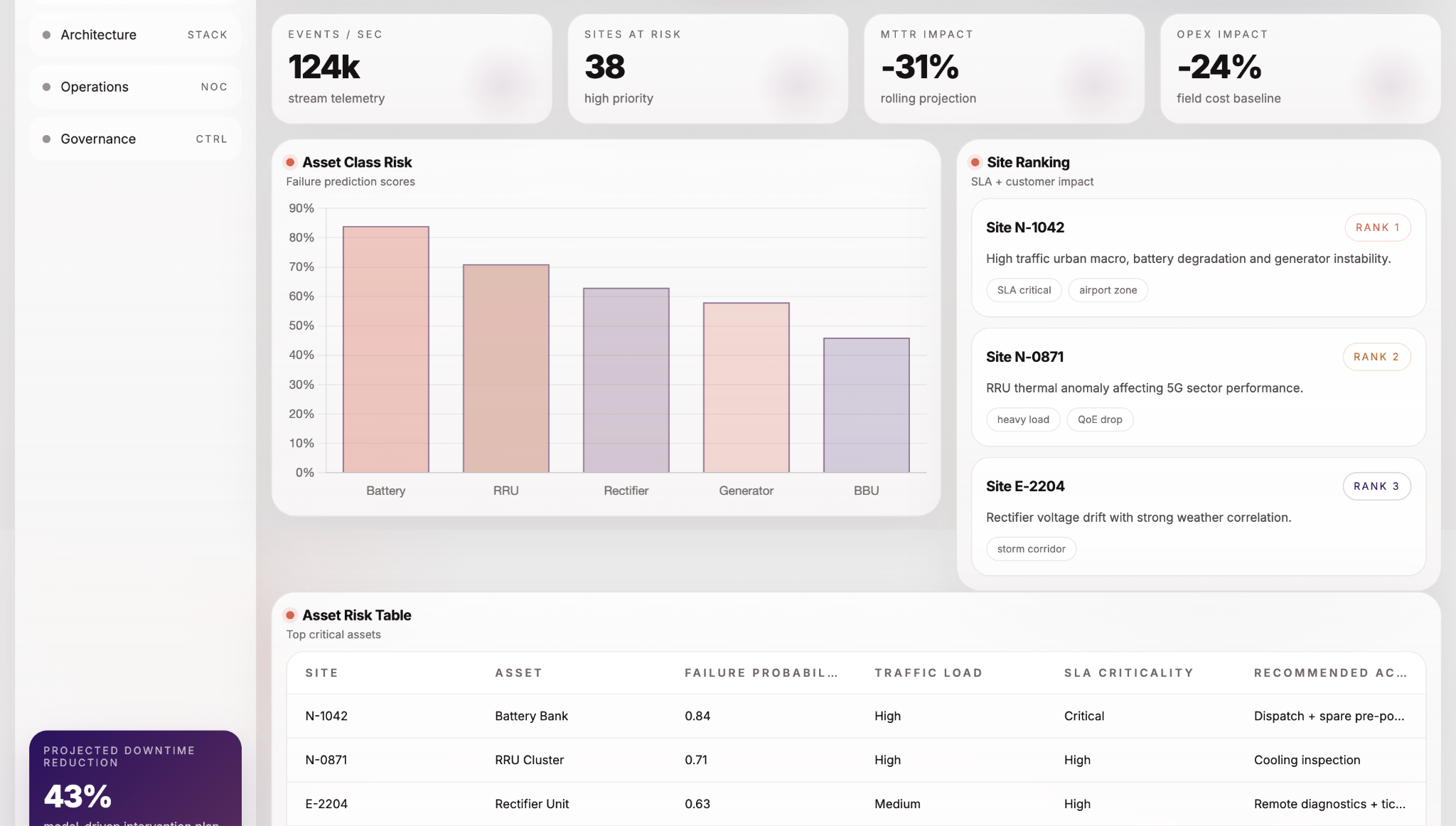
This dashboard provides a centralized view of asset health, failure probability scores, and risk distribution across network sites, enabling operations teams to quickly identify high-risk assets and prioritize intervention.
In addition, the system detects early-stage anomalies such as thermal deviations, voltage instability, and RF signal drift, allowing operators to intervene before faults escalate into service disruptions. By correlating multi-source data — including network telemetry, OSS alarms, weather conditions, and historical maintenance logs — the platform builds a comprehensive understanding of asset behavior.
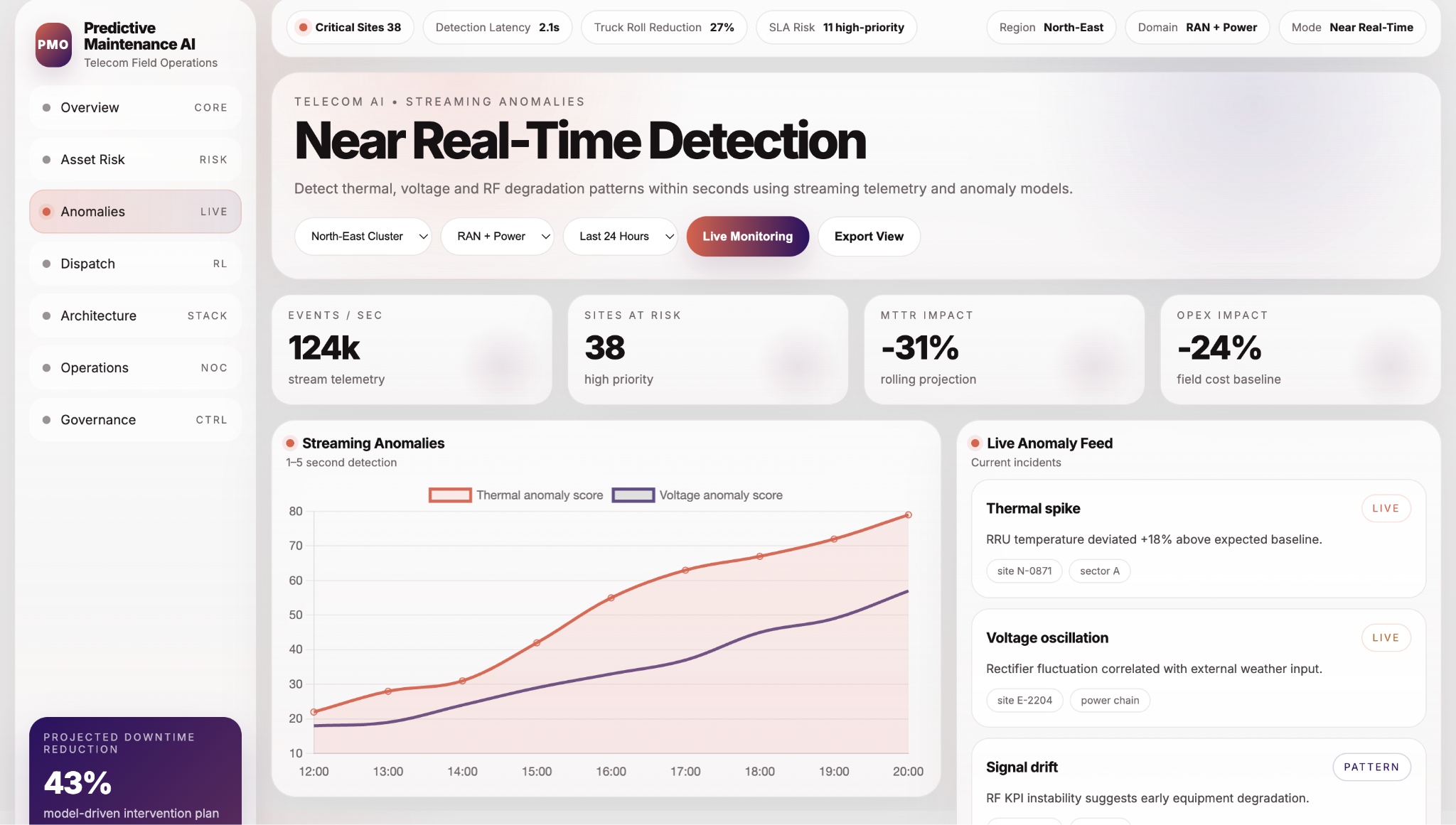
The anomaly detection interface visualizes real-time deviations, alert patterns, and streaming telemetry insights, enabling faster identification of abnormal conditions across the network.
A key component of the platform is the decisioning engine, which assigns a probability of failure to each asset and prioritizes sites based on SLA criticality, traffic load, and potential customer impact. This ensures that operational focus is directed toward the most critical risks at any given moment.
Based on these insights, the system automatically triggers operational actions. These include generating trouble tickets in OSS systems, recommending optimal dispatch strategies for field engineers, scheduling preventive maintenance activities, and enabling proactive spare parts pre-positioning. This level of automation significantly reduces manual intervention and improves response speed.
The platform operates in both real-time and batch modes. Near real-time processing enables anomaly detection and alerting within seconds, while batch processing supports model training, long-term trend analysis, and continuous improvement of prediction accuracy.
Technology Architecture
Scalable Hybrid AI Infrastructure
The solution was implemented as a scalable, hybrid AI platform combining real-time streaming, batch processing, and edge intelligence. The architecture was designed to handle high-volume telecom data flows while ensuring low-latency decision-making and seamless integration with the client’s existing OSS and field operations systems.
At the edge layer, IoT sensors deployed across tower sites continuously collect telemetry data such as temperature, voltage, and RF metrics. Lightweight inference using ONNX Runtime enables basic anomaly detection directly on-site, reducing latency and allowing immediate response to critical deviations.
The data ingestion layer supports high-throughput data streams from multiple sources. MQTT is used for ingesting IoT sensor data, while Apache Kafka acts as the central event streaming backbone, capable of processing tens of thousands of events per second.
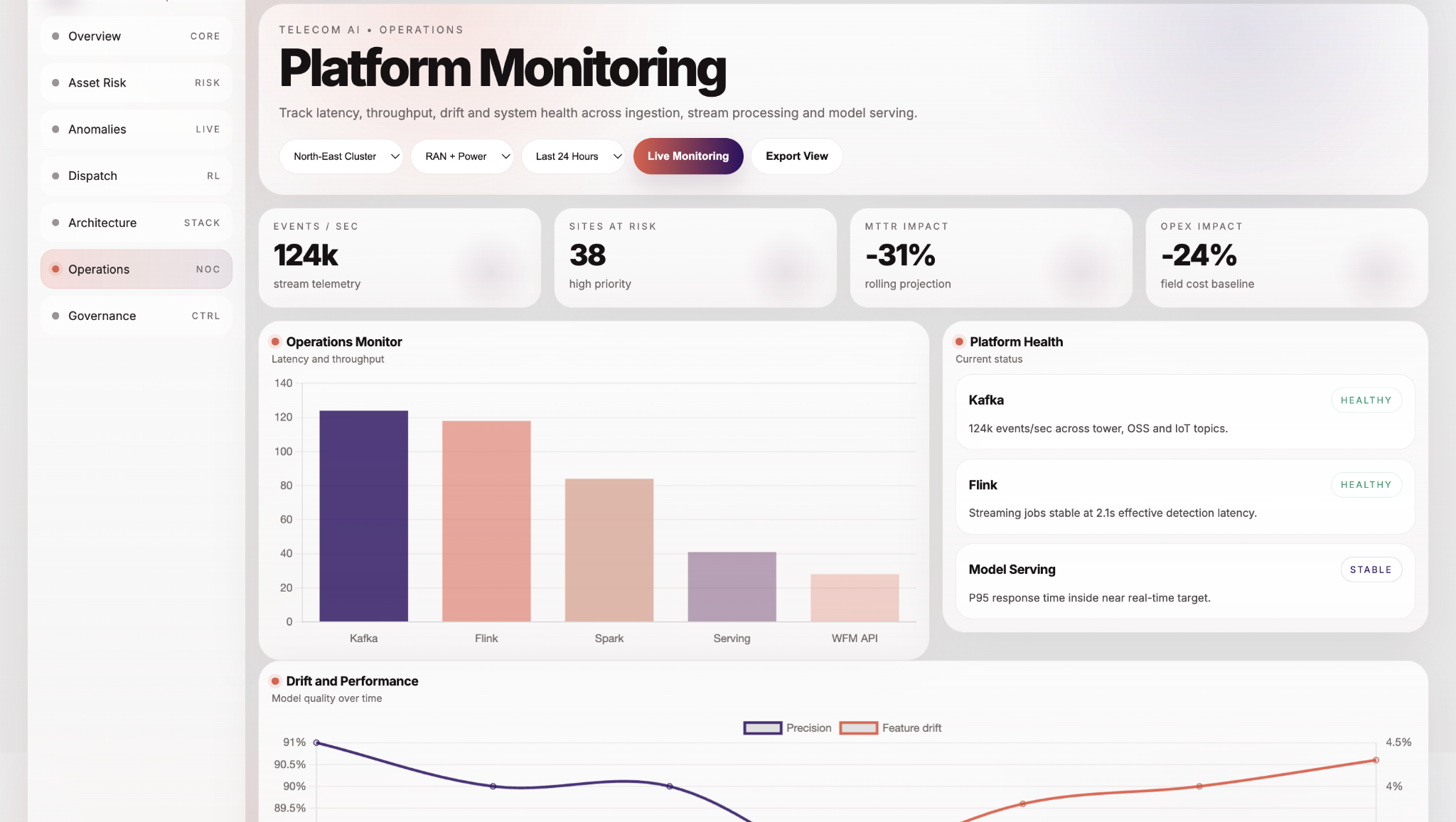
The monitoring interface provides visibility into system performance, data flow, and processing health across streaming and batch pipelines, ensuring reliability and operational transparency.
In the processing layer, Apache Flink handles real-time anomaly detection, scoring, and event correlation, enabling near real-time insights within seconds. In parallel, Apache Spark supports batch processing for feature engineering, historical analysis, and model training pipelines.
The model layer includes a combination of advanced machine learning and deep learning models. Time-series models such as LSTM and Temporal Fusion Transformer are used for failure prediction. Tree-based models like XGBoost and Random Forest perform classification and risk scoring, while anomaly detection is handled by Isolation Forest and Autoencoders. Reinforcement Learning models (PPO/DQN) optimize field dispatch decisions based on dynamic network conditions.
Model serving is deployed in a Kubernetes-based environment, using TensorFlow Serving and PyTorch Serve to expose models via REST and gRPC APIs. This ensures scalability, flexibility, and seamless integration with external systems.
An optimization layer orchestrates dispatch decisions by combining AI predictions with operational constraints such as workforce availability, SLA requirements, and geographic distribution.
The platform integrates directly with OSS systems for ticketing and with Workforce Management (WFM) systems for dispatch execution, enabling full automation of operational workflows.
Observability is обеспечена через Prometheus для метрик і OpenTelemetry для логування та трасування, що дозволяє повністю контролювати продуктивність системи та швидко виявляти будь-які відхилення.
The solution is deployed in a hybrid model (cloud + on-premise), ensuring compliance with telecom data requirements while maintaining scalability. Edge AI capabilities further enhance responsiveness by enabling low-latency inference directly at tower sites.
Results and Impact
Measurable Business
and Operational Outcomes
The deployment of the AI-driven predictive maintenance solution delivered measurable improvements across the client’s network operations, field service efficiency, and overall cost structure. By shifting from reactive maintenance to predictive and proactive operations, the client significantly reduced unplanned outages and improved service continuity across critical infrastructure.
Early fault detection enabled the operations team to identify and address issues before they escalated into service disruptions. This reduced dependency on emergency interventions and allowed for better planning of maintenance activities. As a result, network reliability increased while operational stress on teams decreased.
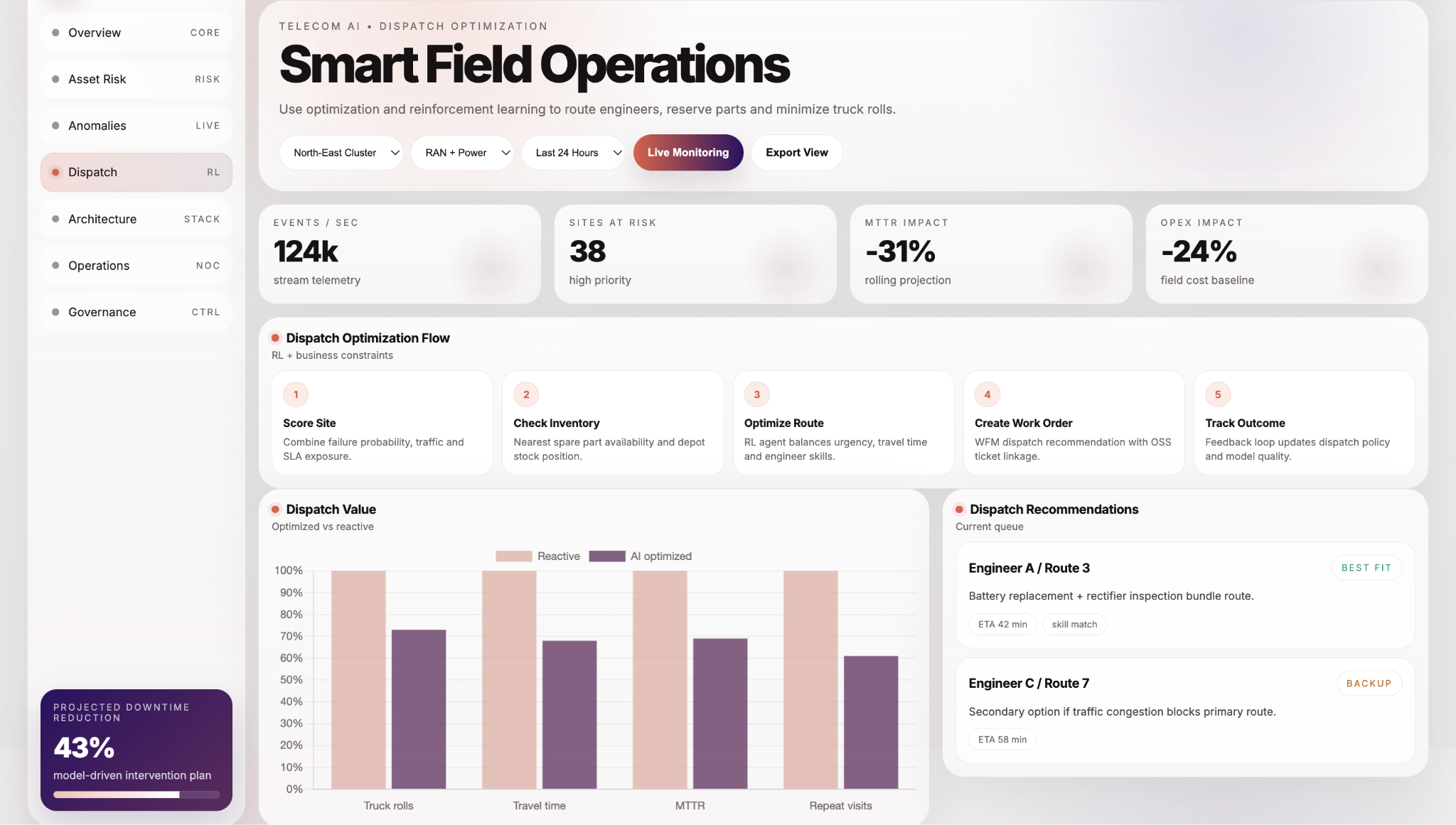
The introduction of intelligent dispatch optimization transformed field operations. Instead of reactive, manual scheduling, the system dynamically recommended the most efficient actions based on asset risk, SLA impact, and resource availability. This minimized unnecessary truck rolls, improved workforce utilization, and ensured that the right engineers were assigned to the right tasks at the right time.
In parallel, operational teams gained real-time visibility into asset health, anomaly patterns, and risk distribution across the network. This visibility enabled faster, more informed decision-making and improved coordination between network operations and field teams.
Overall, the combination of predictive analytics, real-time anomaly detection, and automated orchestration resulted in tangible improvements across both technical KPIs and business outcomes, creating a more resilient, efficient, and scalable operational model for the client.
Key Results
- 30–50% reduction in network downtime, driven by early fault detection and proactive maintenance
- 20–35% reduction in field service costs due to optimized dispatch and fewer unnecessary truck rolls
- Up to 43% decrease in unplanned outages through predictive failure prevention
- ~31% improvement in MTTR (Mean Time to Repair), enabling faster issue resolution
- Detection latency reduced to 1–5 seconds, allowing near real-time anomaly identification
- 40–60% reduction in manual operational effort through automation of workflows and decisioning
- 100% end-to-end visibility across network assets, telemetry streams, and field operations
- 15–25% improvement in SLA adherence, reducing penalties and improving customer experience
- 20–40% reduction in overall operational costs (OPEX)
- 2–4x ROI achieved within 6–12 months of deployment
Conclusion
Transformation to Proactive Operations
The implementation of the AI-driven predictive maintenance platform enabled the client to fundamentally transform their telecom operations model. Instead of relying on reactive, failure-driven maintenance, the organization transitioned to a proactive, intelligence-driven approach where risks are identified and addressed before they impact network performance.
By combining time-series forecasting, anomaly detection, and reinforcement learning, the solution provides continuous visibility into asset health and enables smarter, faster operational decisions. The client is now able to predict failures in advance, optimize field operations in real time, and significantly reduce unnecessary interventions and associated costs.
The platform also introduces a controlled and transparent operational environment, where deployment, monitoring, and decision-making processes are fully governed and traceable. This ensures reliability, scalability, and alignment with enterprise-level requirements.
Overall, the solution establishes a strong foundation for resilient and data-driven network operations. It delivers immediate business value through improved SLA performance and reduced operational costs, while also positioning the client for long-term scalability and competitive advantage in an increasingly complex telecom landscape.



Our success stories














































Tell us about your project needs











.png)
.png)