



The table of content
Executive Summary
Dietsmann engaged Infinity Technologies to implement an AI-driven predictive maintenance system for critical rotating equipment at a gas processing facility. The objective was to reduce unplanned downtime, improve equipment reliability, and transition maintenance operations from time-based scheduling to condition-based decision making.
Infinity Technologies deployed a production-grade predictive maintenance platform integrated directly with the facility’s SCADA and maintenance systems. The system continuously analyzes sensor data from rotating equipment, predicts failures before they occur, estimates remaining useful life, and automatically generates maintenance recommendations.
Within the first six months of operation, the system prevented three major equipment failures, reduced unplanned downtime by 34 percent, and delivered a return on investment within eight months.
Business Challenge
The facility operated continuously and relied on several critical rotating assets:
- centrifugal gas compressors
- process pumps
- electric motors
- cooling system fans
Failures of these assets resulted in:
- production interruptions
- emergency maintenance
- high repair costs
- safety risks
Prior to the project, maintenance was performed using fixed service intervals and alarm thresholds defined in the control system.
This approach created three operational issues:
- Failures were detected too late
- Maintenance was often performed unnecessarily
- Equipment reliability was unpredictable
Over a 12-month period, the facility experienced:
- 17 unplanned equipment shutdowns
- average downtime per incident: 6.4 hours
- estimated production loss: 2.1 million USD
Dietsmann required a predictive system capable of identifying equipment degradation before failure occurred and providing clear operational guidance to maintenance teams.
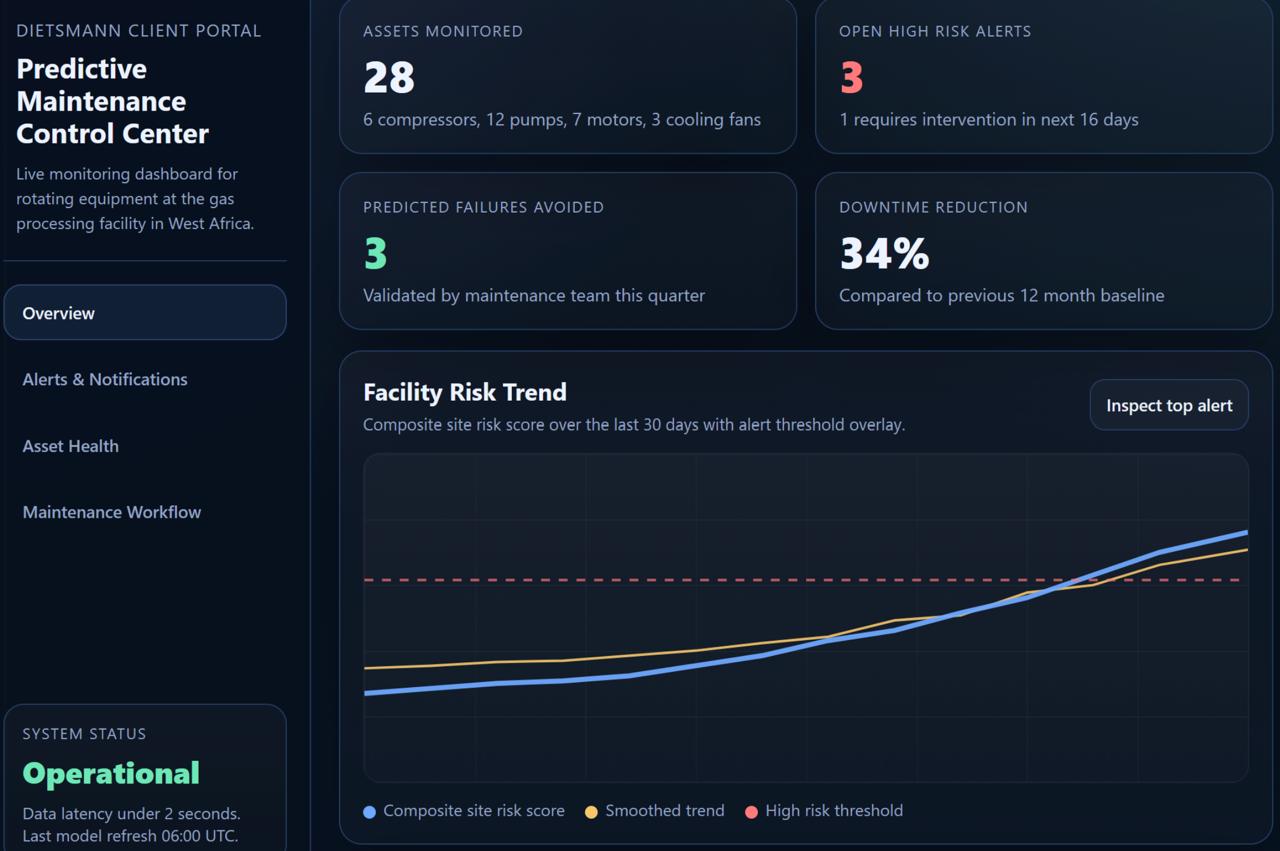
Solution Delivered
Infinity Technologies designed and implemented a fully operational predictive maintenance platform for rotating equipment.
The system continuously monitors equipment behavior, detects abnormal patterns, predicts failures, and recommends maintenance actions.
The platform was deployed as a production system and integrated into the existing operational environment.
Equipment Covered
The system was deployed on 28 critical rotating assets:
- 6 centrifugal gas compressors
- 12 process pumps
- 7 electric motors
- 3 cooling tower fans
These assets were selected based on:
- operational criticality
- failure history
- maintenance cost
- production impact
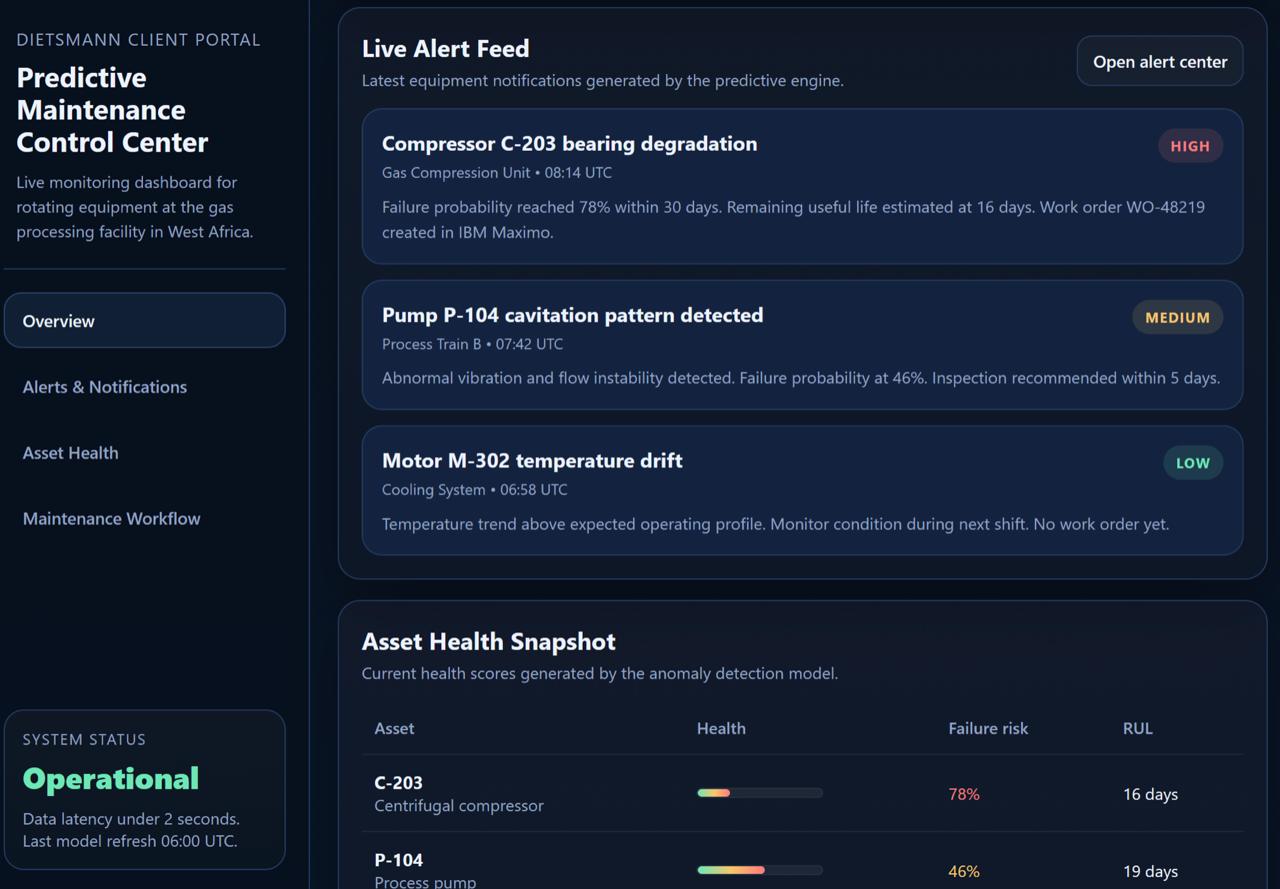
Data Integration
Infinity Technologies integrated the predictive maintenance platform directly with the facility’s operational systems.
Data sources included: SCADA system Schneider Electric EcoStruxure
Industrial communication protocols: OPC-UA and Modbus TCP
Sensor data collected:
- vibration amplitude
- vibration frequency spectrum
- bearing temperature
- motor current
- shaft speed
- pressure
- flow rate
- runtime hours
Data sampling frequency: 1 sample per second
Daily data volume: Approximately 12 million records

System Architecture
The system was deployed on the client’s existing infrastructure and operated continuously.
Data ingestion layer: Apache Kafka
Time-series database: TimescaleDB
Processing environment: Python
Machine learning framework: PyTorch
Visualization platform: Grafana
Deployment model: On-premise industrial server cluster
Availability: 24/7
Latency: Less than 2 seconds
Machine Learning Implementation
Infinity Technologies developed and deployed three production models.

Model 1 - Anomaly Detection
Purpose: Identify abnormal equipment behavior in real time.
Model: Autoencoder neural network
Training data: 18 months of historical sensor data
Update frequency: Every 6 hours
Output: Equipment health score from 0 to 100
Model 2 - Failure Prediction
Purpose: Predict probability of equipment failure.
Model: Gradient Boosting (XGBoost)
Prediction horizon: 30 days
Output: Failure probability percentage
Example output: Compressor C-203
Failure probability: 78 percent within 30 days
Model 3 - Remaining Useful Life Estimation
Purpose: Estimate time remaining before failure.
Model: Survival analysis regression
Output: Remaining useful life in days
Example output: Pump P-104
Remaining useful life: 19 days
Confidence level: 86 percent
Workflow Integration
The system was integrated directly into the maintenance workflow.
When the system detected a high-risk condition:
- An alert was generated
- A maintenance recommendation was created
- A work order was automatically issued
Integration system: IBM Maximo
Notification channels:
- SMS
- Operations dashboard
Implementation Timeline
Phase 1 Discovery and Data Assessment
Duration: 3 weeks
Activities:
- Asset selection
- Data availability validation
- Infrastructure assessment
- Risk analysis
Phase 2 System Development
Duration: 7 weeks
Activities:
- Data pipeline development
- Model training
- Dashboard design
- Integration configuration
Phase 3 Pilot Deployment
Duration: 6 weeks
Scope: 10 critical assets
Activities:
- Model validation
- Performance testing
- Operational tuning
Phase 4 Full Deployment
Duration: 8 weeks
Scope: All 28 assets
Activities:
- System rollout
- Staff training
- Operational handover
Example Incident Prevented
Asset: Centrifugal compressor
Location: Gas compression unit
Observed condition: Gradual increase in vibration at bearing assembly
Traditional system: No alarm triggered
AI system: Detected abnormal vibration pattern
Prediction: Bearing failure expected within 16 days
Recommended action: Replace bearing during scheduled maintenance
Result:
- Failure prevented
- No production interruption
Estimated cost avoided: 482,000 USD
Operational Results
Measured over six months of production use.
Unplanned downtime reduction: 34 percent
Maintenance cost reduction: 21 percent
Emergency repairs reduction: 41 percent
Equipment availability increase: 6.2 percent
Mean time between failures improvement: 27 percent
False alarm rate: Less than 4 percent
System uptime: 99.8 percent
Financial Impact
Annual savings achieved: 1.9 million USD
System implementation cost: 420,000 USD
Return on investment: 8 months
Five-year net financial benefit: 8.6 million USD
Organizational Impact
The project changed how maintenance decisions were made.
Before implementation: Maintenance decisions were reactive.
After implementation: Maintenance decisions became data-driven.
Operational changes included:
- maintenance planning based on predicted risk
- reduced emergency maintenance
- improved reliability planning
- better spare parts management
Maintenance teams began using predictive dashboards as a standard operational tool.
Technology Stack Used
Data ingestion: Apache Kafka
Database: TimescaleDB
Machine learning: PyTorch
Predictive modeling: XGBoost
Visualization: Grafana
Integration: IBM Maximo
Deployment: On-premise Linux cluster
Monitoring: Prometheus



Our success stories






























.avif)











































Tell us about your project needs











.png)
.png)